
In this paper we present an approach to virtual actors in games that we believe will make it easier for audiences to willingly suspend their disbelief.
Today a similar situation pertains to how characters move in real-time graphics applications, such as computer games. Character motion generally consists of canned movements, which have been either key-frame animated, or else motion-captured from human performance.
A deficiency of these approaches is that to an audiences it is very obvious when a character is using canned movements, since the same exact movements will appear again and again. The result is a loss of the "willing suspension of disbelief" that would allow an audience to easily pretend that an actor is experiencing a given inner psychological state.
We describe an alternate procedural approach to real-time virtual actor movement which proceeds "from the inside out." In our approach, actor movement and posture is always informed by an inner psychological state. Rather than being animated by canned movements, the actor always appears to be psychologically present; all movements convey the actor's continually varying mixture of moods and goals.
In other word, technical limitations drove the aesthetics of the content. Shortly after the release of TRON, the author introduced the ideas of procedural noise and the use of a procedural shading language [Perlin85]. This approach allowed programmer/designers to write simple programs, now called "shaders," which would run at each visible point of a computer graphic object. Below we can see several different procedural shaders applied to different portions of a sphere.
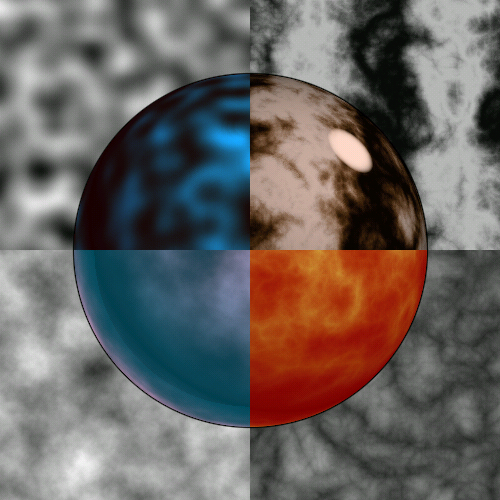
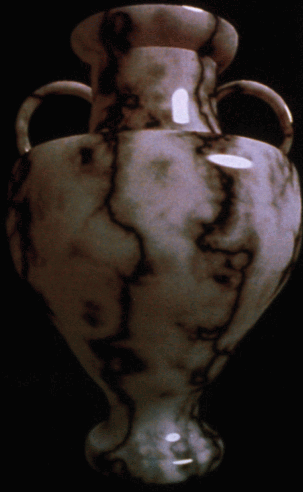
This approach allowed designers to incorporate the sort of controlled randomness we associate with natural surfaces and materials, as in the marble vase below.
Similarly, it is possible to create a "texture" of intentional movement. Since the late 1980's we have been exploring this approach to human movement that conveys personality. Before describing this work, it is important to examine the question of agency.
Where is the agency?
A central question in dealing with interactive characters is the question of where agency is situated. In other words, who has the power to decide what happens next? Is this decision made by the character in the narrative, or by the observer of the narrative? In a more traditional linear story form, such as a novel or cinematic film, the observer has little or no power to change the course of events. In a trivial sense, the reader of a novel can skip around or peek at the ending, and the viewer of a film can walk out or come in in the middle, but the audience really has not ability to effect the choices made by characters in the story, within the reality presented by that story.
The structure below represents this dichotomy:
|
(agency in the story) |
???
|
(agency within you) |
There is an interesting contrast with the development of the character of Lara Croft from the game Tomb Raider. When Tomb Raider was just a game, Lara Croft herself was really just a game token. The user made all the decisions (run, jump, shoot). There was a backing story to the game, explaining who Lara Croft was supposed to be, but that strong-willed character was not what the player of the came encountered.
Then the movie came out, and for the first time people could finally meet this intelligent and strong-willed character about whom they had only read. But in this incarnation, it was impossible for people to interact with Lara Croft. Once brought to life, she became fixed and immutable.
Who do we bridge this gap? How do we create a character about whom we care, and yet with whom we can interact in psychologically interesting ways? The key issue is believability. Note that this is not at all the same as realism. For example, the character of Bugs Bunny is quite believable, in the sense that we have a pretty good idea about his internal psychological makeup, his attitudes, what he would plausibly do when faced with a given new situation. Yet he is not at all realistic: were Bugs Bunny to walk in the door of your house, you would probably need to rethink your view of reality.
A key way to frame this issue is to ask what the character is doing when you are not there. For example, when we play Tomb Raider, we don't have a sense of what Lara Croft the game character would do while we are not playing. That is because we have not seen her make any choices; in the course of game play, we have made all the choices for her. Therefore we have not built a model in our heads of what she herself might do. We literally have no idea who she really is.
On the other hand, when we put down a Harry Potter book, we have a visceral sense of the continuing presence of Harry Potter, and his life at Hogwarts School. J.K. Rawling has given us a compelling illusion that her novel is merely a peek into a continuing world, in which many other adventures are happening just around the corner and slightly off the page. In some sense, we know who Harry Potter is.
The key difference, again, is that Lara Croft in the game Tomb Raider has no agency, where has Harry Potter in one of Rawling's novels has complete agency. So the creation of psychologically compelling interactive narrative must solve the following puzzle: How do we create characters who have intermediate agency? In other words, characters who can be somewhat responsible for their own actions, but about whom we can also be somewhat responsible?
A limited illusion of this is neatly conveyed by the characters in the game The SIMS, designed by Will Wright. The major limitation of the "actors" in The SIMS is that all of their movement consists of predesigned sequences of linear animation. For example, if a young mother in The SIMS is playing with her baby, and the player tells her to feed the baby, she will respond by putting down the baby, thereby ending the "playing with baby" animation. Then she will pick the baby up again to begin the "feeding baby" animation. While the larger story is indeed being conveyed, the movement itself is highly unbelievable. The player does not end up feeling as though the mother character has an inner life or sense of motivation. Instead, the mother character is positioned in the player's mind as a game token embodied as a moving doll figure, switching unthinkingly from one discrete state to another.
We have done a number of experiments in the last few years to create characters that can have a more layered set of behaviors. Let us go back to the notion of procedural texture, but apply it to human movement rather than to visual appearance. Intentional movements (walking, reaching, etc.) can be combined and layered with procedurally generated pseudo-random movements that signify continuing presence, such as weight shifting and blinking,
This was the basis for the Improv project at NYU [Perlin96]. Below are shown a few characters in that system.



The principles underlying the behavior of these characters were: Layered behavior Subsumption architecture Good "fuzzy" authoring language Controlled randomness
Much of this work was turned into a line of commercial products by Improv Technologies for non-linear animation. They were designed to be complementary to the standard animation tools, such as Alias Maya, 3D Studio Max, etc.
Some more recent experiments conducted by the author include studies of interactive dance, of facial animation, and of embodied actors that interact with each other while conveying mood, intention and personality. In particular, one experiment concerned analyzing and synthesizing facial affect. The questions asked here were as follows: What are the simplest components that will convey effective and believable human facial affect? How are these components effectively combined to make a language? What would be the simplest such language that would still be effective?
We found that a small number of degrees of facial freedom could be combined to make a large emotive space of facial expressions. In a sense, simple expressions such as "mouth open", "eyes wide", "sneer", etc., can be thought of as notes on a kind of emotional instrument. More complex facial expressions are created by playing combinations of these notes together, to create chords, or even arpeggiated chords.







We also applied this idea of building "emotional chords" from simpler emotive components to the synthesis of fully embodied emotionally expressive humanoid actors. We followed the following basic principles to allow an embodied actor to convey personality. Rather than simply stringing together linear animations, we create activity components (which serve the same approximate function as "verbs"), as well as affect components (which serve the same approximate function as "adverbs"). The key to making this approach effective is to have a run-time architecture in which a simulated actor is always running. The movements and posture of the actor are continually adjusting to reflect changes in a maintained inner "mood state".
At a high level of abstraction, an actor performs the following tasks in succession in order to create each individual frame of the interactive animation: First the actor determines his global position and the direction he needs to be heading in the scene. This decision is generally made to conform with the general blocking of the scene, resulting from a negotiation between the actors in the scene and a director agent.
Then the actor figures out the approximate joint angles of the limbs his body should assume (elbow, shoulder, spine, etc), so as to convey the particular mood and action he is trying to convey. For example, various emotional signifiers can be conveyed by such postural attributes as shoulders thrust back, elbows kept out or in, back curved or straight, head or hips tilted. At this stage, the actor also figures out an optimal weight shift between his two feet.
Next he determines where he should ideally place his "contact parts": those parts of his body that need to be in contact with the world. Most of the time these are hands and feet. Then he uses the above info to compute what all his joint angles should be. This process will generally result in the proper bodily attitude, but will not place his contact parts in the proper place.
Finally, he does a simple inverse kinematics computation for his contact parts, so that hands, feet, etc., touch or grip the external objects that they need to contact. The inverse kinematics needs to be the very last step because contact constraints are "hard" constraints which must be maintained exactly.
The interesting part of the above is the process of maintaining bodily affect. This is handled through a number of competing controller processes, each of which is jockeying to try to maintain some constraint (shoulders back, spine twisted halfway, etc.). These attitude signifiers continually shift in importance as the actor varies his mood and focus of attention. Because these constraints are always in competition with each other, at any moment in time they will settle into an optimal negotiated configuration that reflects the actor's internal process at that moment.
Below is a sequence of images from a simple rendering of an interactive scene played by two of these actors. Note how the body language of each actor shifts from moment to moment, to convey what that actor is emotionally expressing.
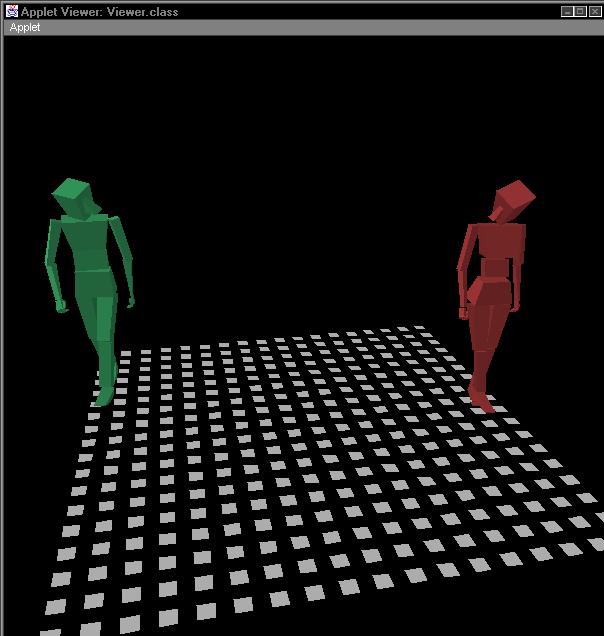
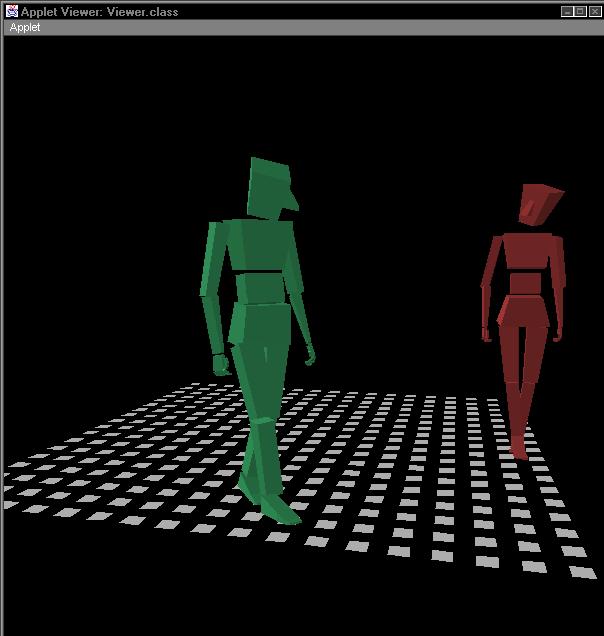
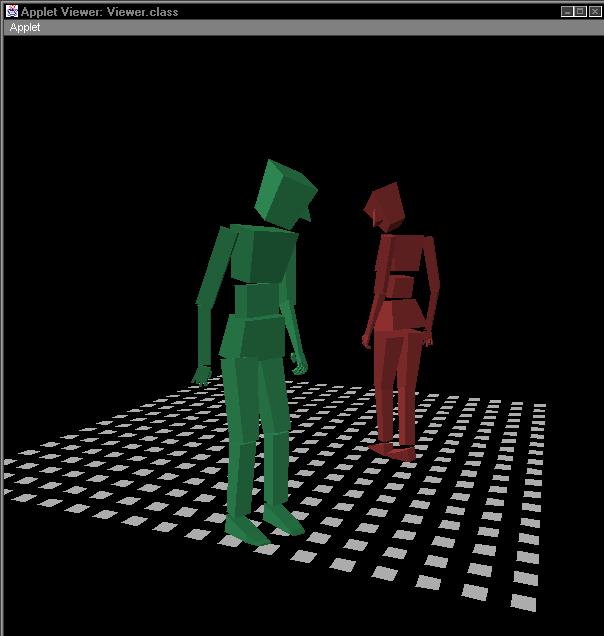
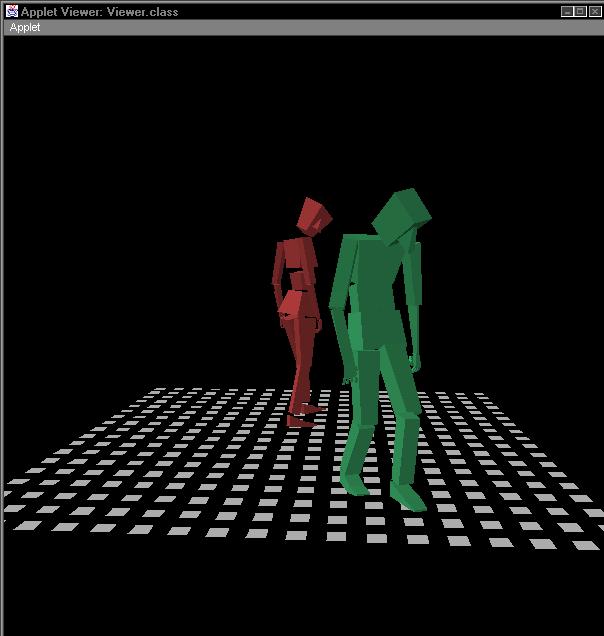
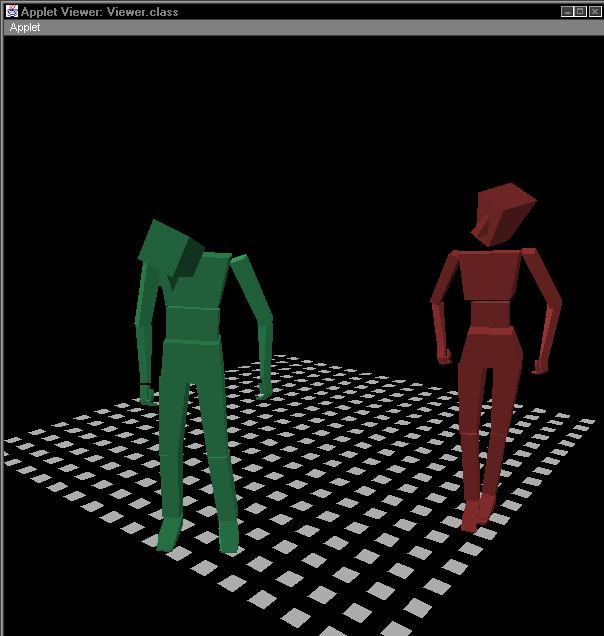
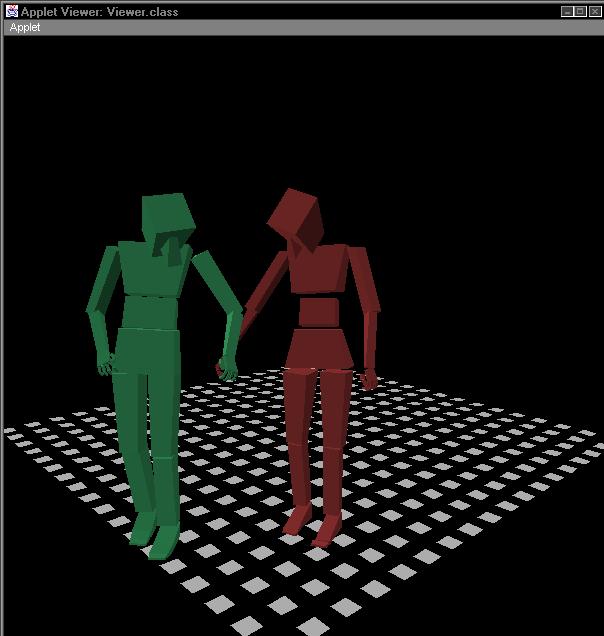
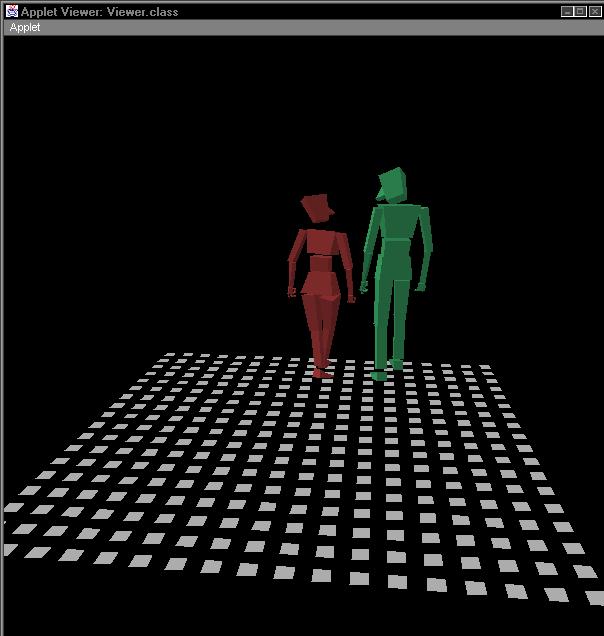
This style of actor can change the nature of how interactive narratives are structured. It becomes much more important to create to think of the actor's inner process when creating the narrative, then it would be in the typical computer games of today. Even simple operations such as reaching for an object or turning to look at another actor can become infused with meaning, since the actor is constantly making little adjustments in pose and body language to "sell" an interior emotion.
It becomes possible for the same action to convey such higher level ideas as being in love, encountering one's natural enemy, being in a sacred place, or even just having had a great breakfast.
One key to fully exploiting this approach for creating psychologically compelling interactive narratives will be to allow different kinds of authors to work in complementary layers. At the bottom layer is the enabling technology, which allows actors to convey believable personality and body language within a real-time game engine. Above this is the set of choices that defines a particular actor. The next layer up is the set of choices that defines a particular character.
We anticipate that there will be three distinct kinds of people who will be interacting with these actors. The first could be called professional actor builders. They will actually dig down and create the body language, particular pauses and hesitations, quirks of movement, that enable an actor to "sell" a character. Then there are power users, who do not go as deep as professional actor builders, but can develop new moves and routines, working in a higher abstraction layer. Finally, there will be most users, who will function as directors.
What comes next? The key is to get We are currently getting the actor simulation to work within the Unreal engine. This will allow these actors to be used in Machinima movies. Ultimately, we would like to enable a genre that has some of the richness of The SIMS, but with much more expressivity and personality in its characters.